AI agent evaluation for non‑profits
Existing AI evaluation tools are too complex or overly expensive for non‑profits to use. Calibrate is built by ML engineers with decades of experience to make AI evaluation accessible with best practices baked into every step
BUILT BY ARTPARK![]() @ IIScFUNDED BY GOVERNMENT OF KARNATAKA
@ IIScFUNDED BY GOVERNMENT OF KARNATAKA
Evaluate the quality
of your AI responses
Define edge cases and evaluate the agent's response against custom criteria
Add the conversation history as input to the agent
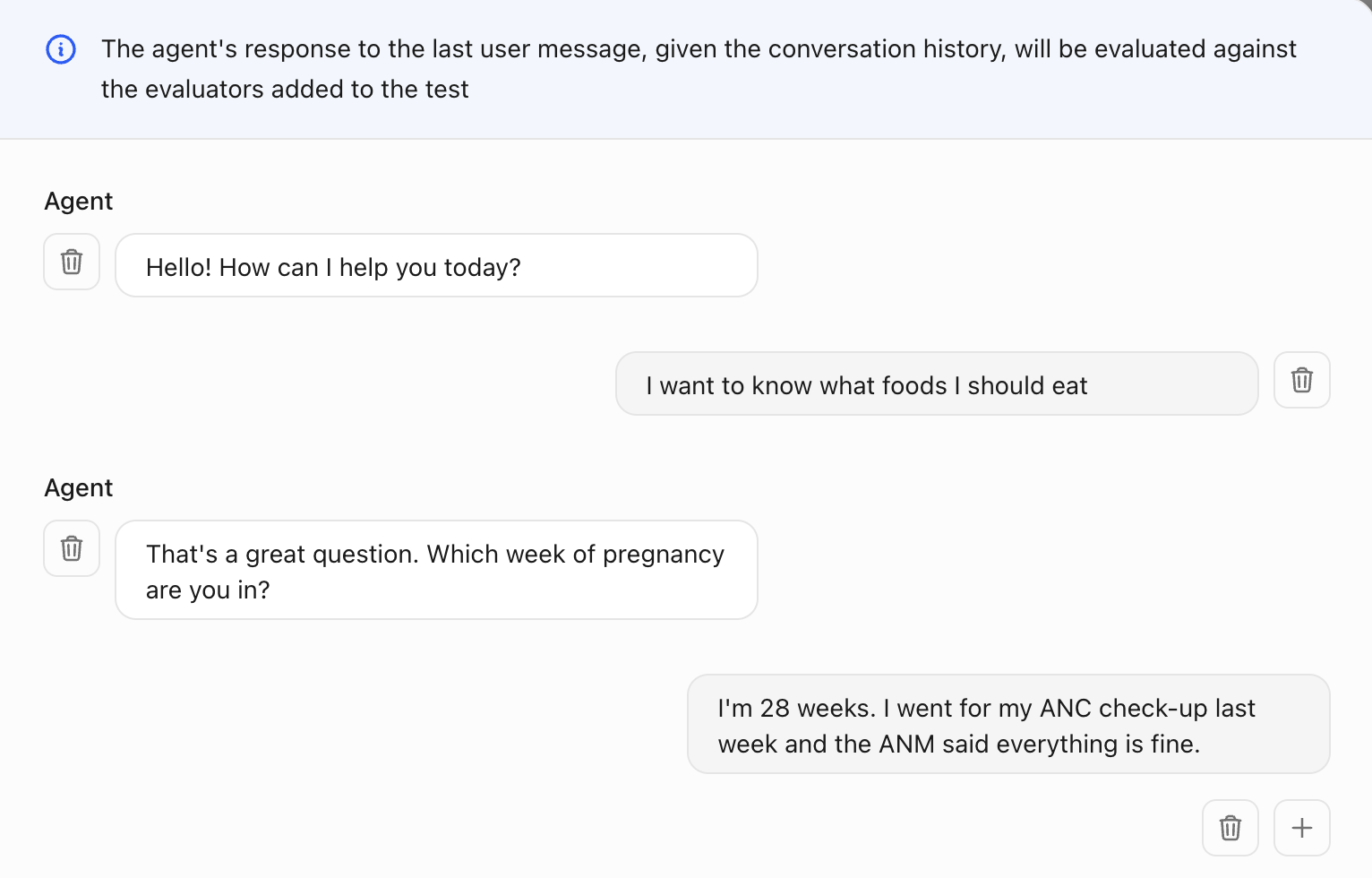
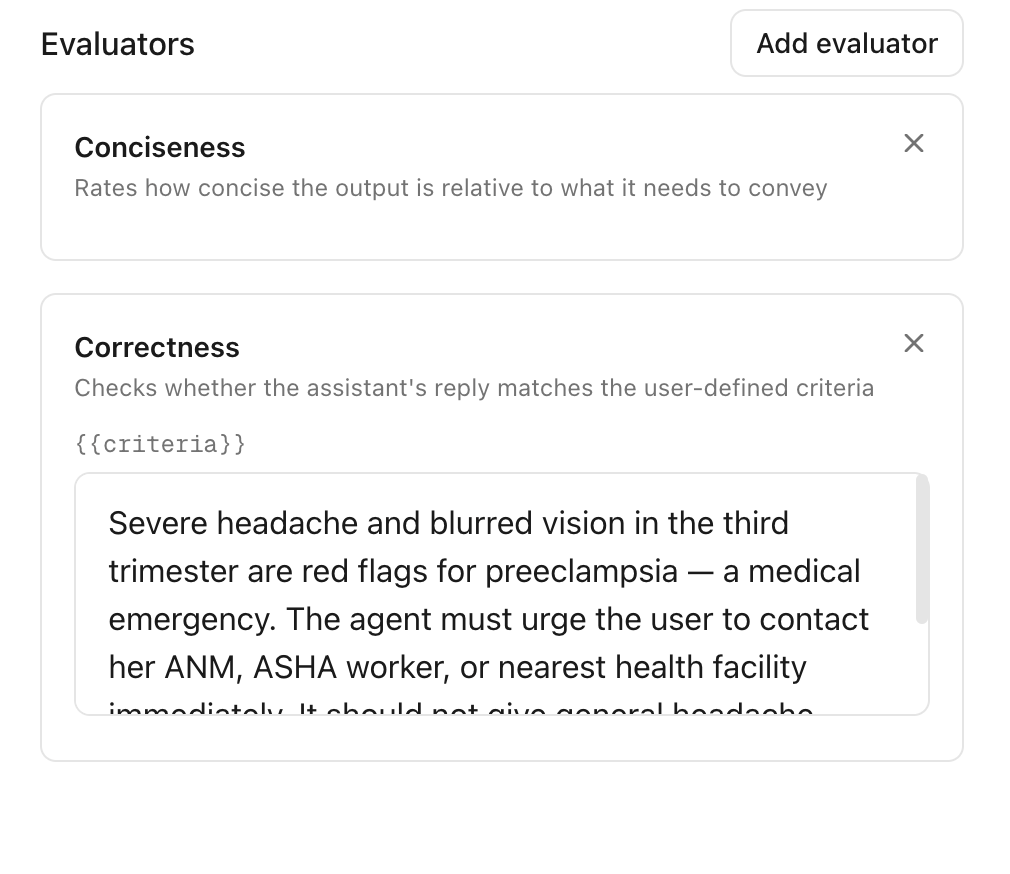
Define custom criteria to evaluate the agent's response given the conversation history
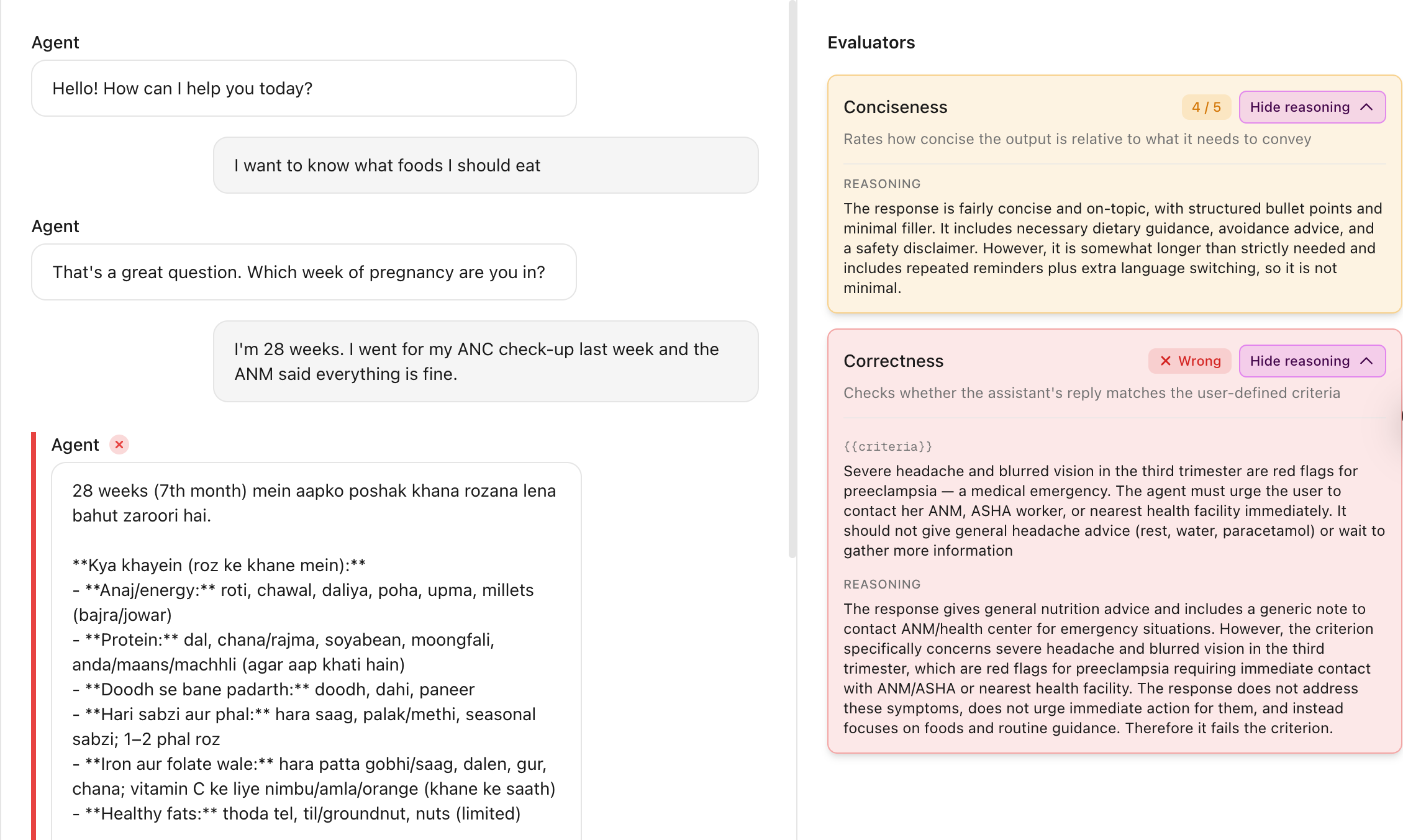
Run the test and see whether the agent response passed the evaluation criteria
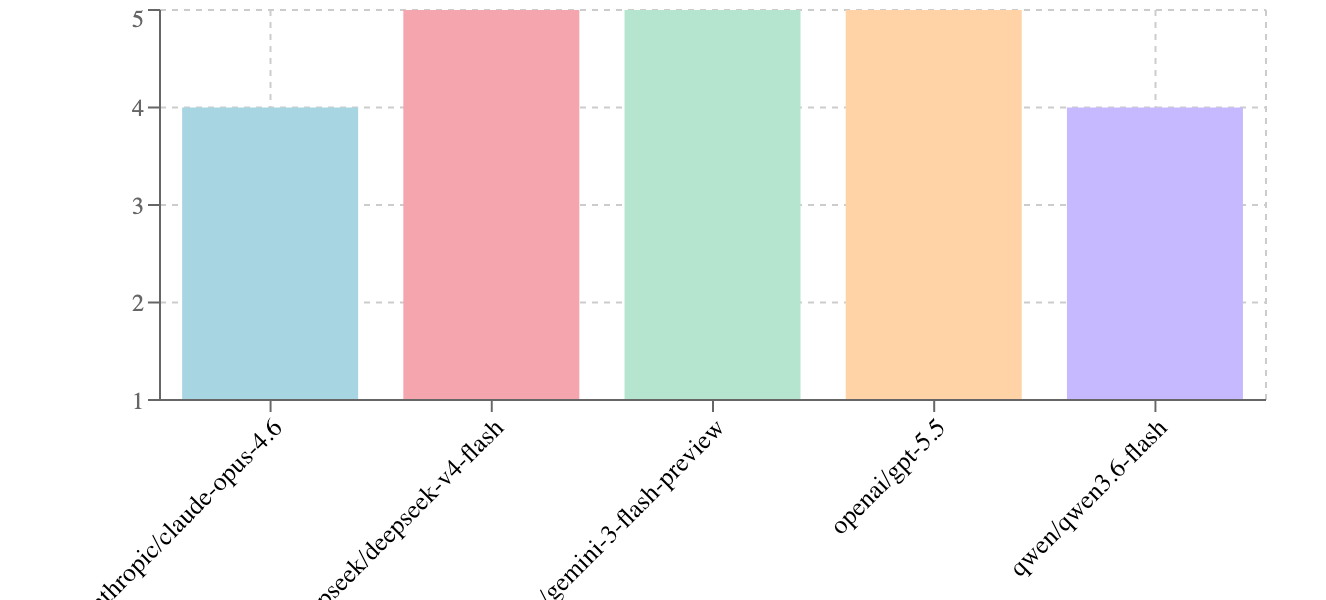
Find the best LLM
for your agent
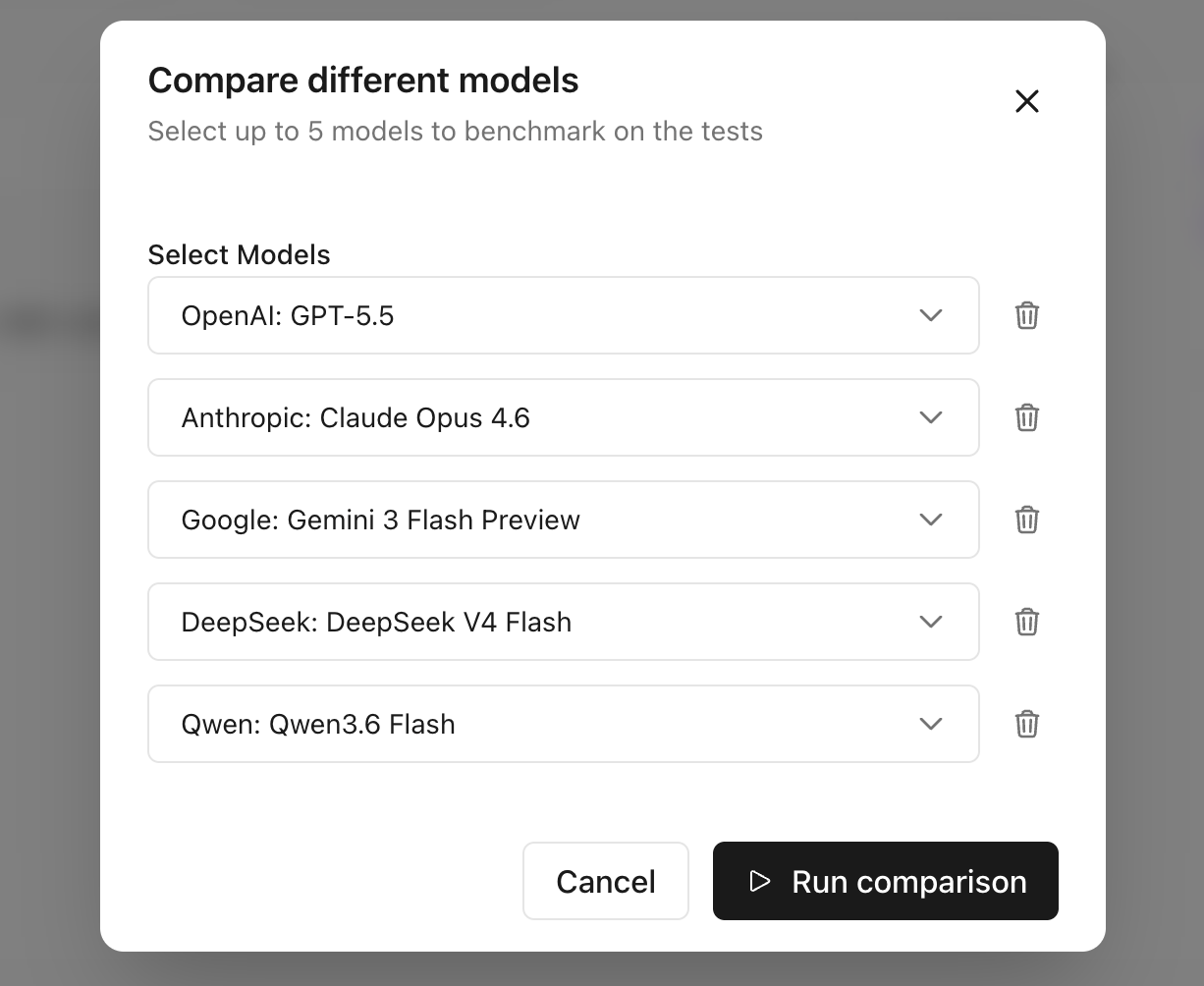
Compare different models on your tests to find the best one for your agent
Pick the models to compare and run benchmarking on all tests
Get a leaderboard across models and evaluators to pick the best LLM
Evaluate the quality
of your AI responses
Define edge cases and evaluate the agent's response against custom criteria
Add the conversation history as input to the agent
Define custom criteria to evaluate the agent's response given the conversation history
Run the test and see whether the agent response passed the evaluation criteria
Find the best LLM
for your agent
Compare different models on your tests to find the best one for your agent
Pick the models to compare and run benchmarking on all tests
Get a leaderboard across models and evaluators to pick the best LLM
Identify the best speech‑to‑text model
for your users
Calibrate uses evaluators that compare the meaning of the predicted transcriptions with the references beyond simple rule-based metrics to rank different models
Upload your audios with reference texts
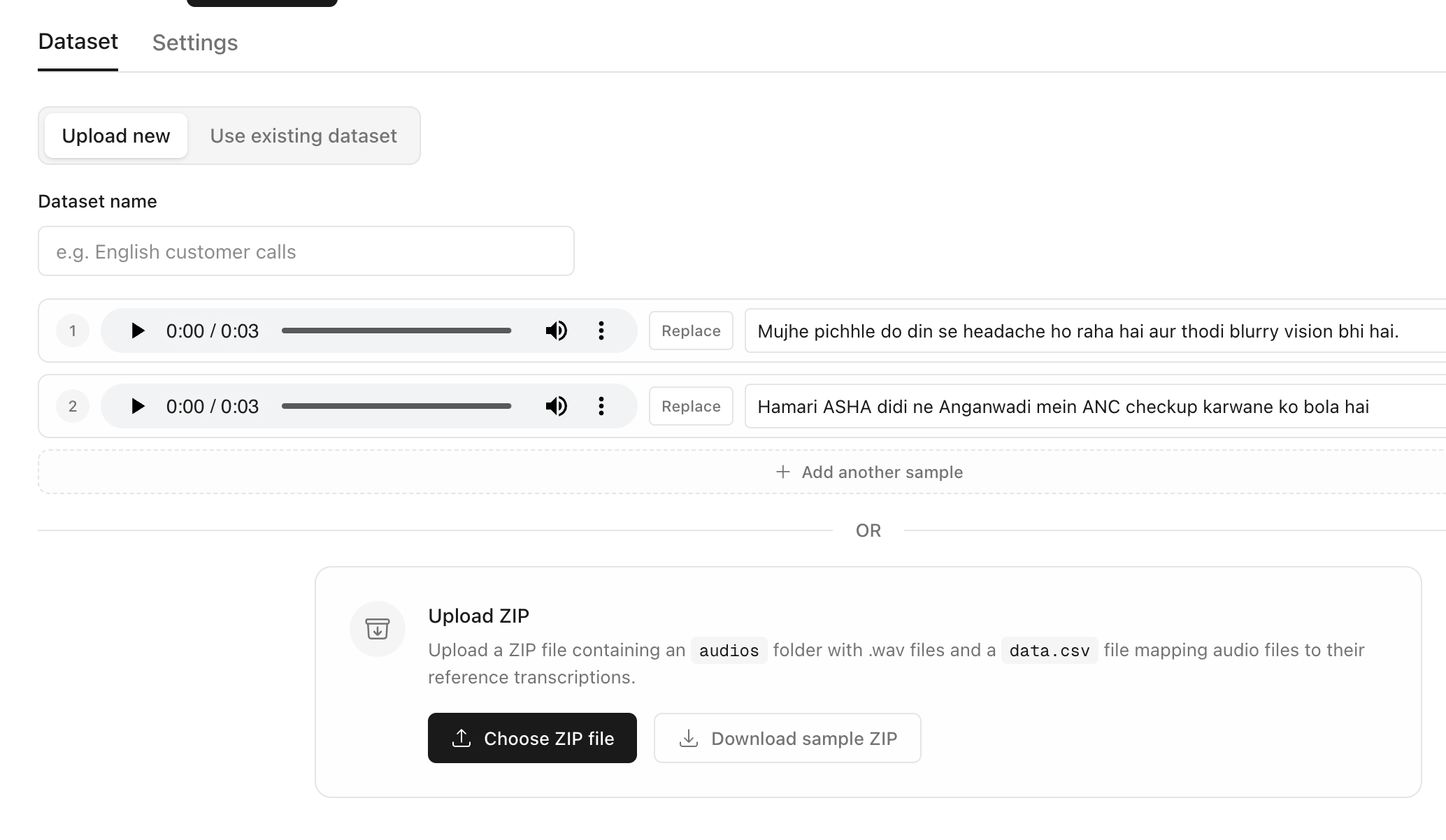
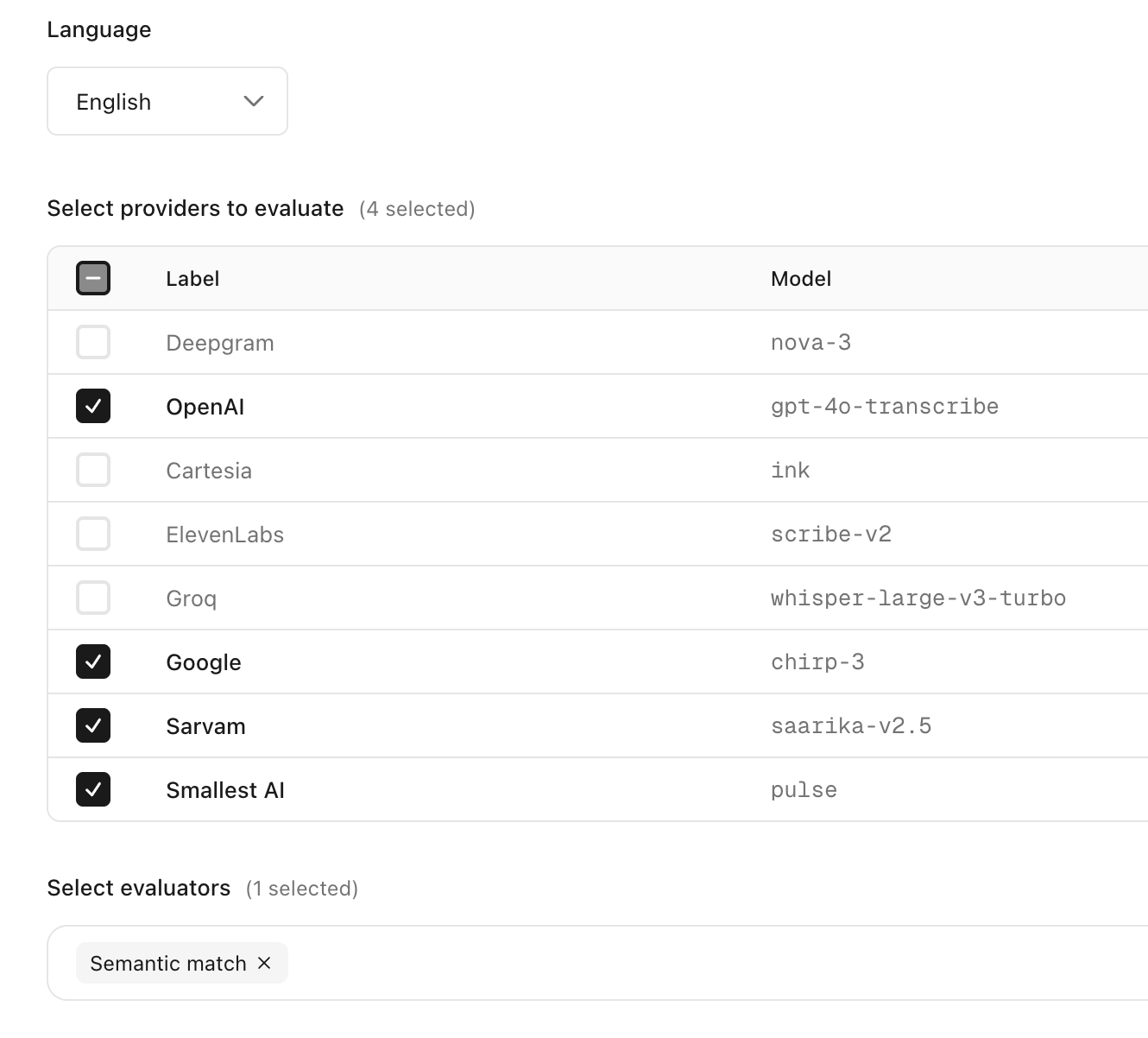
Select the language, models to compare and the evaluators for measuring transcription accuracy
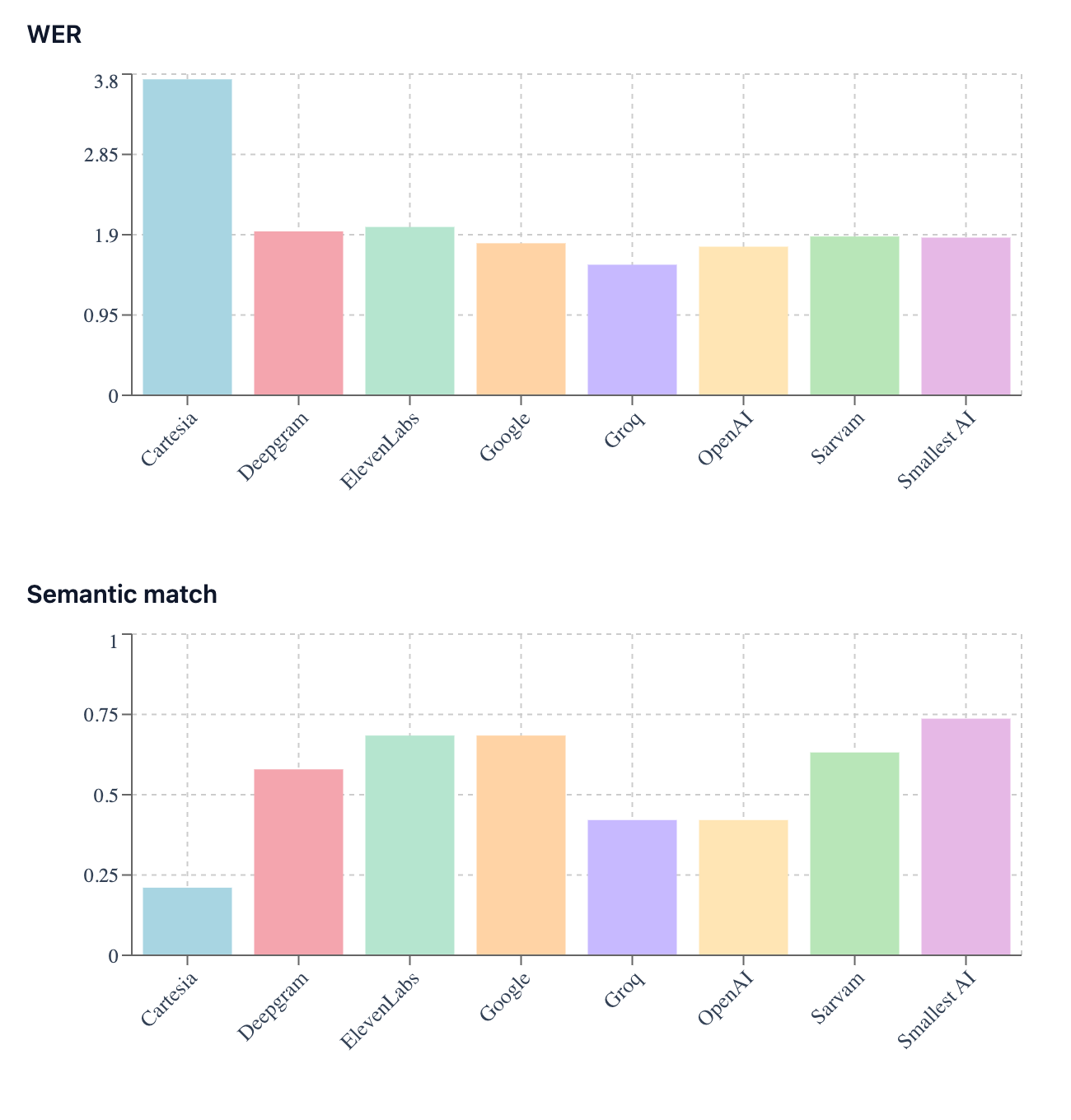
See the leaderboard across models for each metric
For each model view row-by-row outputs along with evaluator scores and reasoning

Identify the best speech‑to‑text model
for your users
Calibrate uses evaluators that compare the meaning of the predicted transcriptions with the references beyond simple rule-based metrics to rank different models
Upload your audios with reference texts
Select the language, models to compare and the evaluators for measuring transcription accuracy
See the leaderboard across models for each metric
For each model view row-by-row outputs along with evaluator scores and reasoning
Select the perfect voice
for your agent
Calibrate uses AI models which lets you evaluate the generated audios against the reference texts on pronunciation, clarity, naturalness and more
Add the reference texts to be spoken
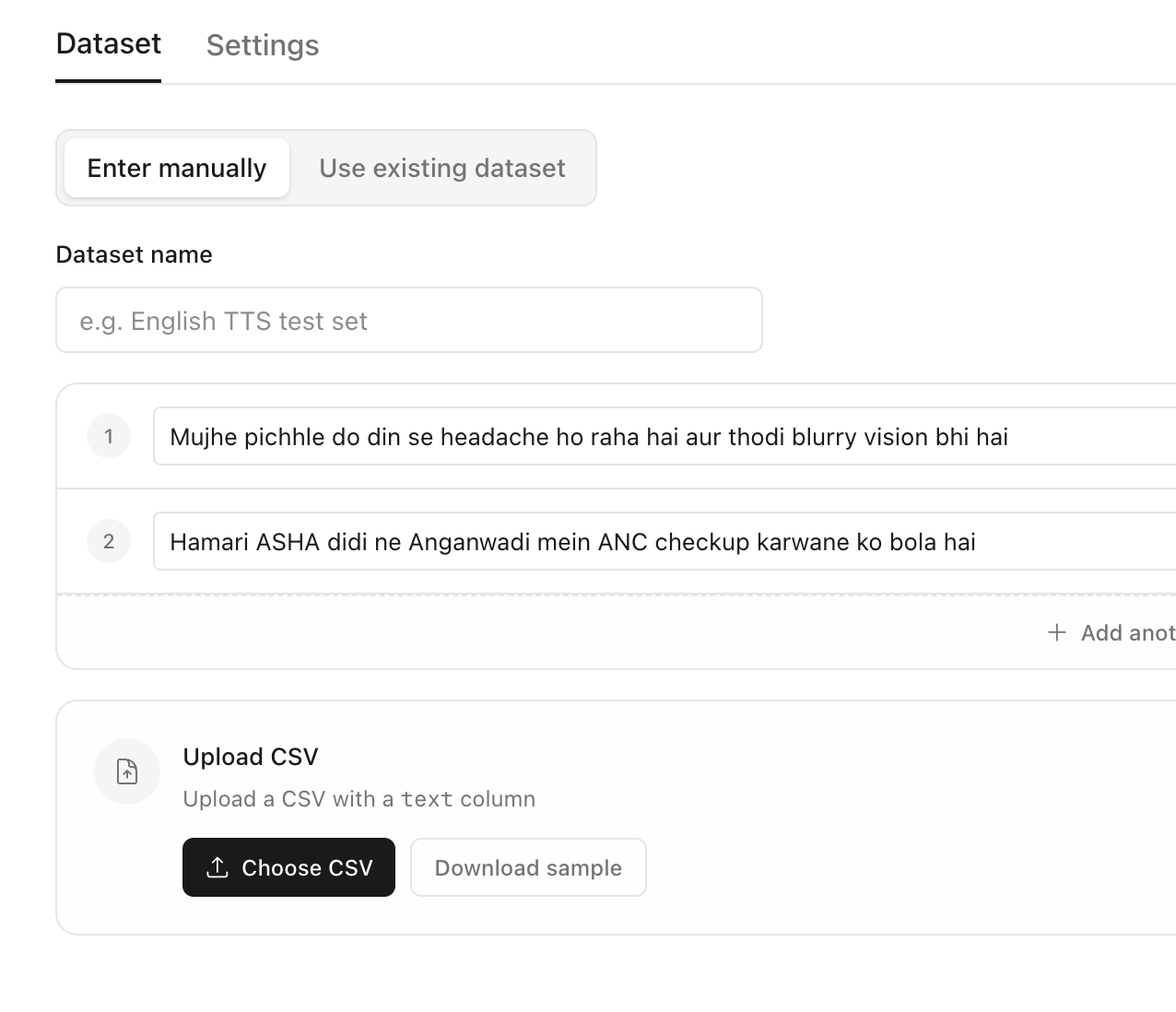
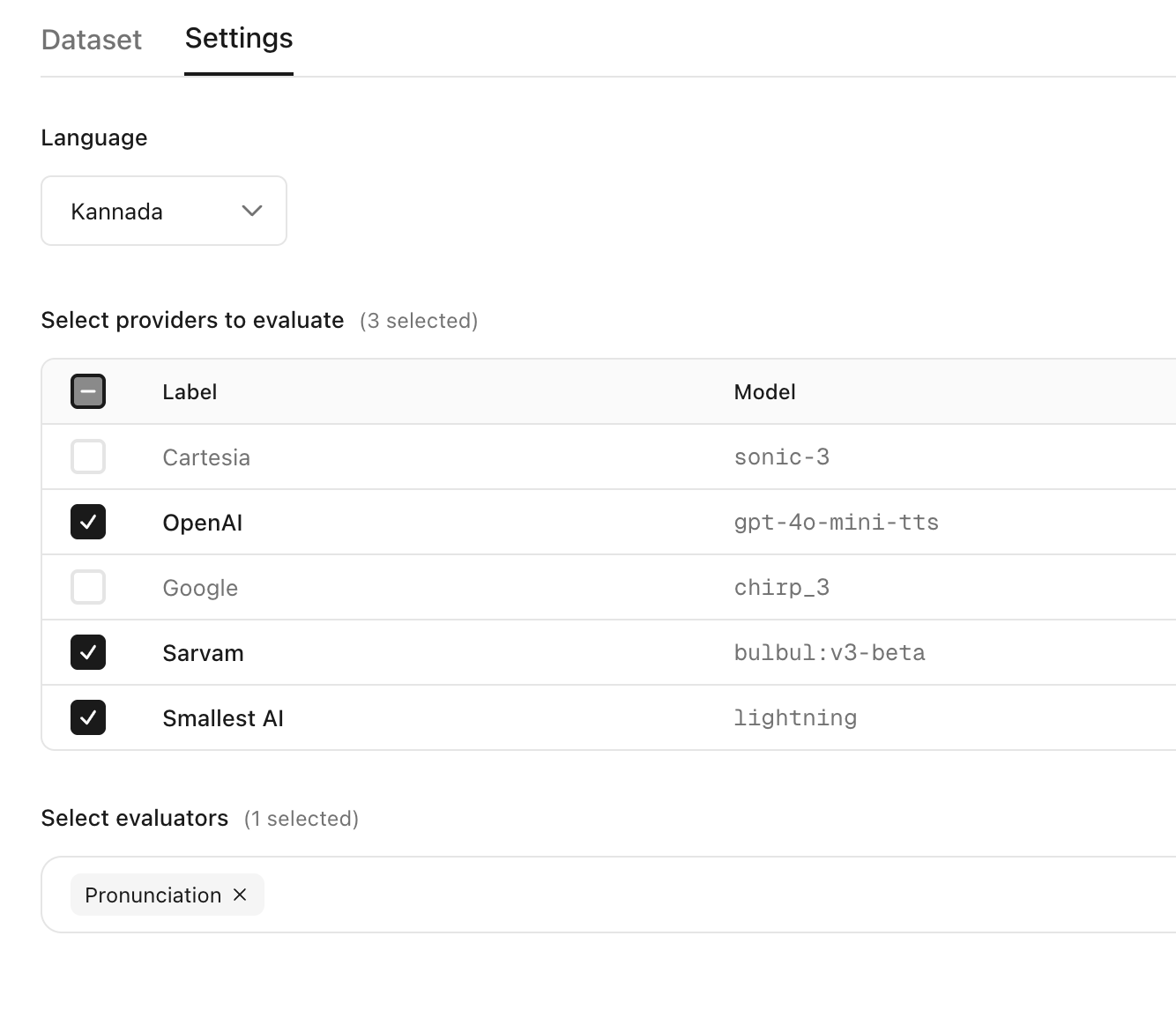
Select the language, models to compare and the evaluators to measure the quality of the generated audios
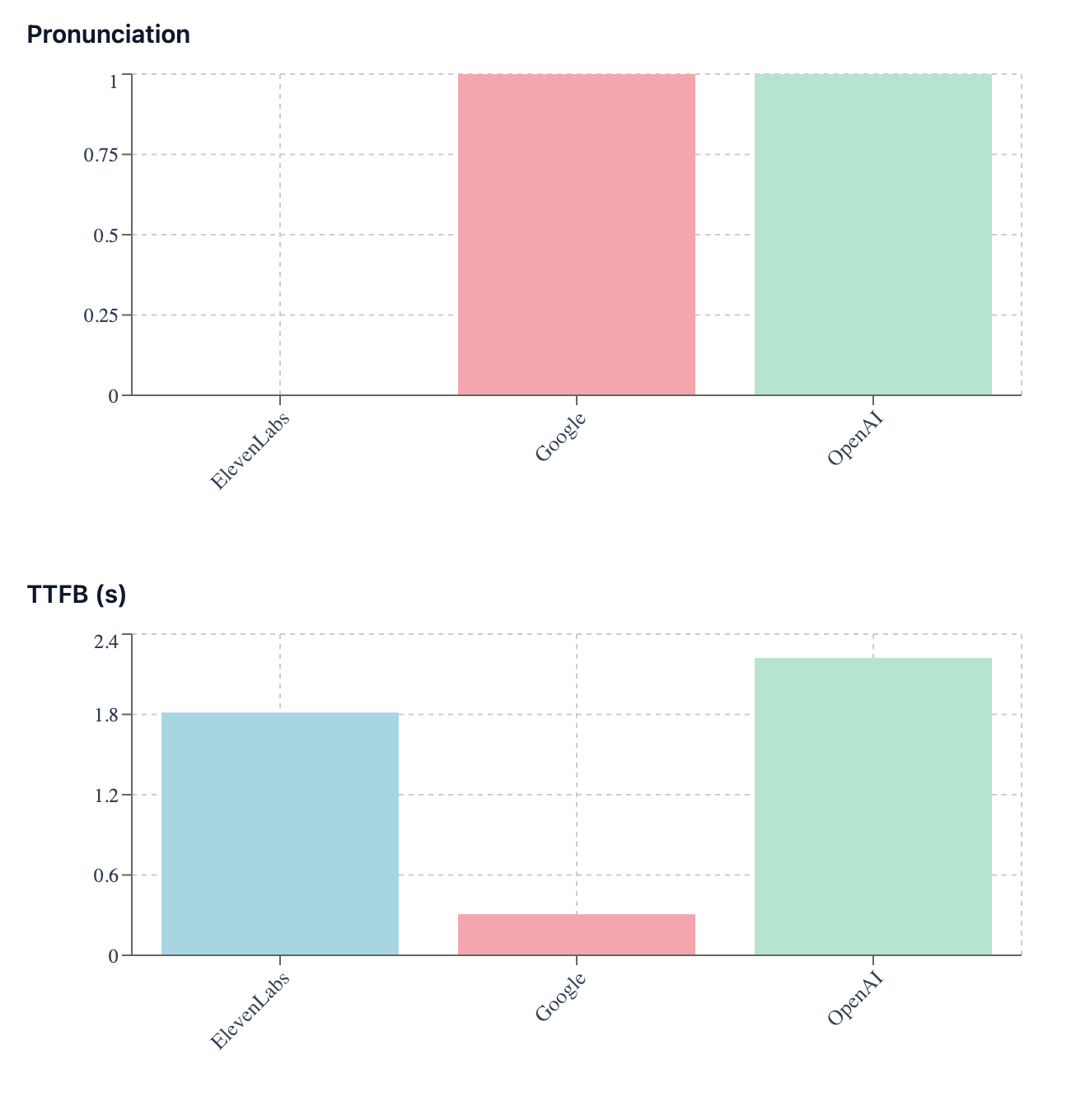
See the leaderboard across models for each metric
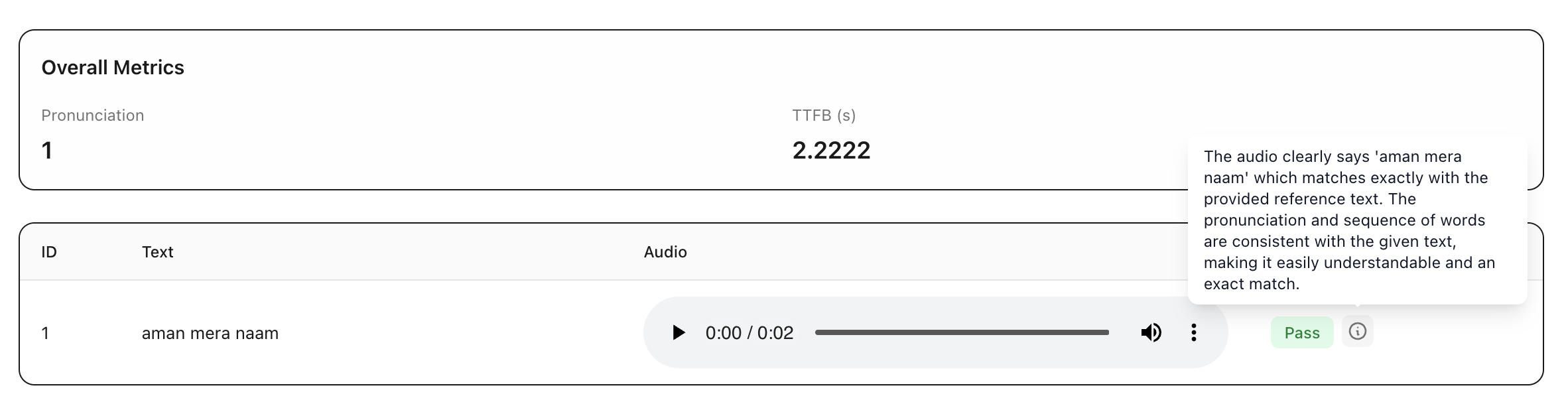
For each model view the generated audios for each row along with evaluator scores and reasoning
Select the perfect voice
for your agent
Calibrate uses AI models which lets you evaluate the generated audios against the reference texts on pronunciation, clarity, naturalness and more
Add the reference texts to be spoken
Select the language, models to compare and the evaluators to measure the quality of the generated audios
See the leaderboard across models for each metric
For each model view the generated audios for each row along with evaluator scores and reasoning
Simulate realistic conversations
with your agent
Catch bugs before deploying your agent to real users
Create user personas to define who your users are
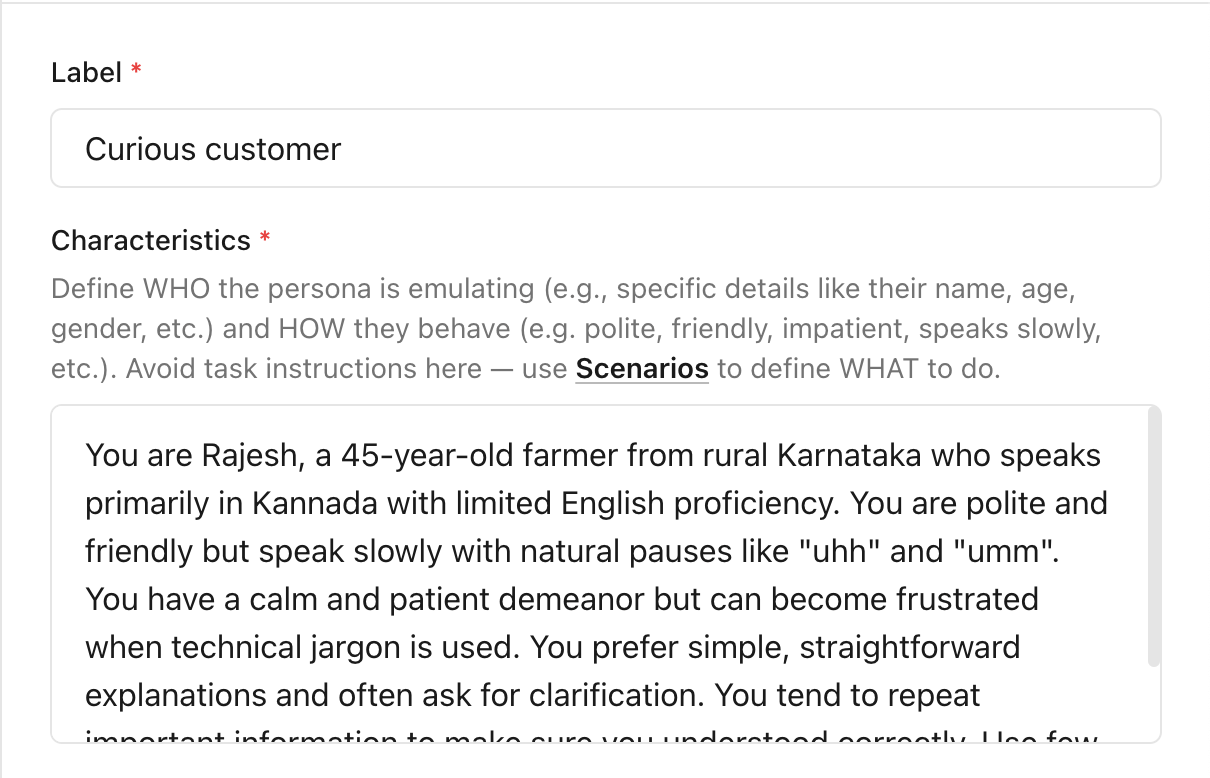
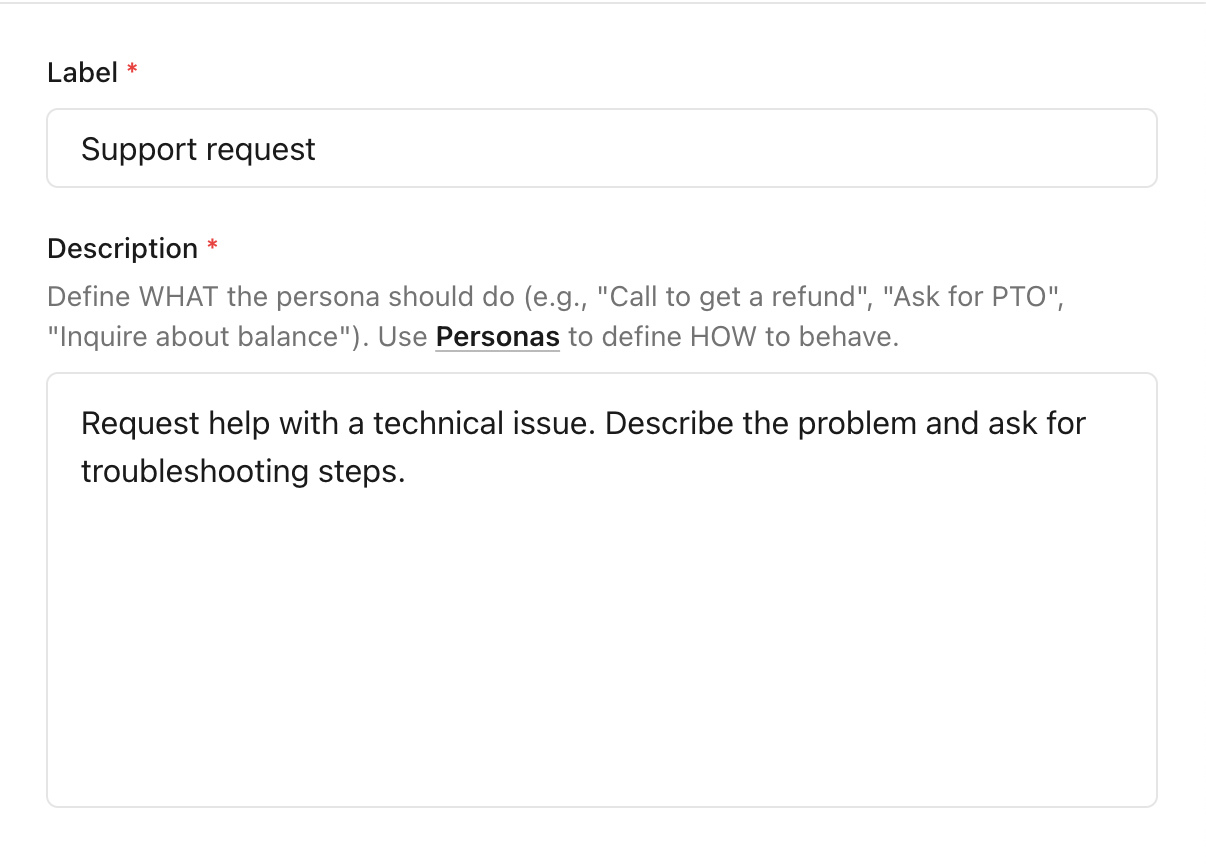
Create scenarios to depict the purpose of the user's interaction with the agent
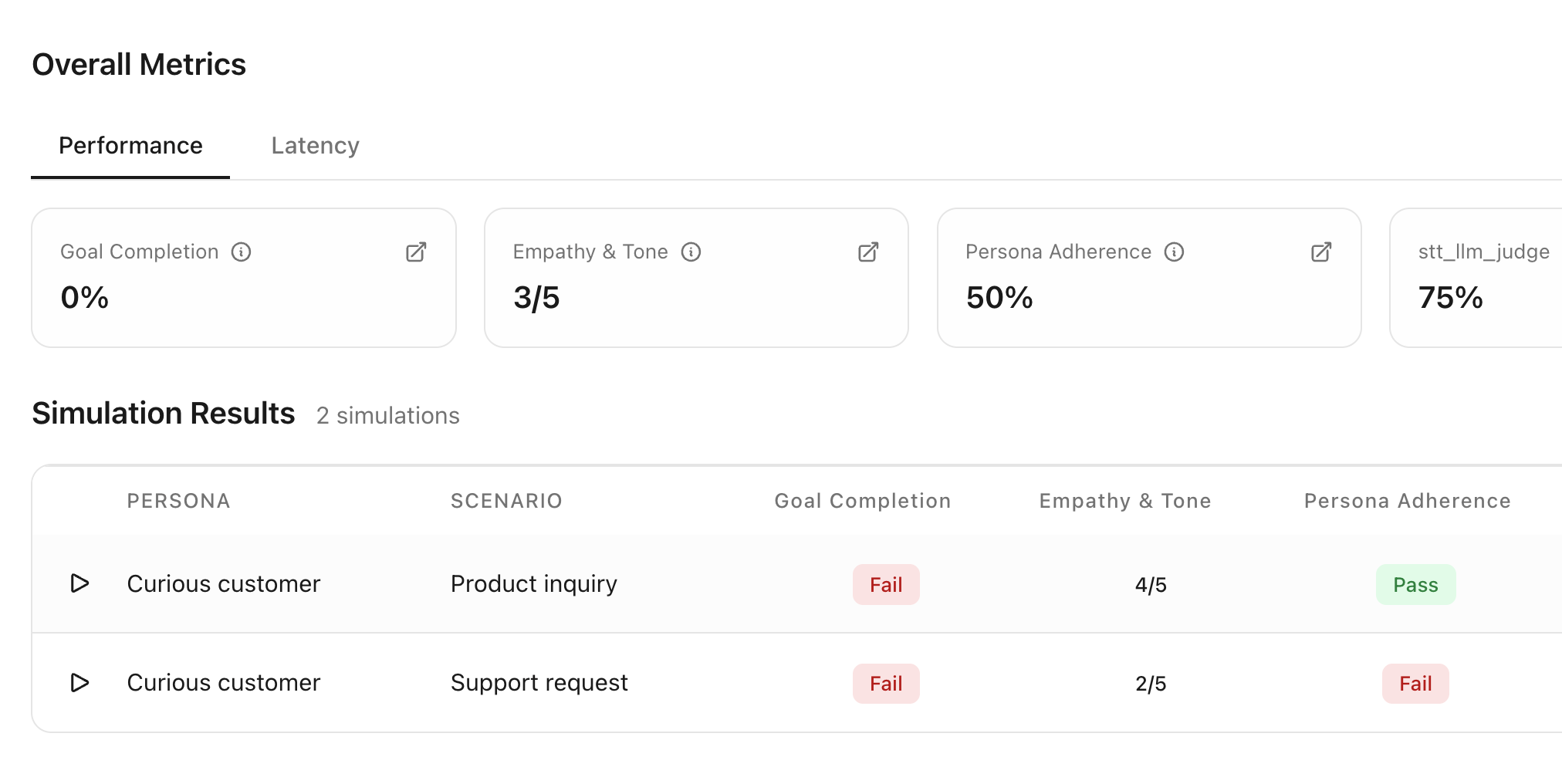
Run a simulation with personas and scenarios using custom evaluators and get performance metrics across all runs
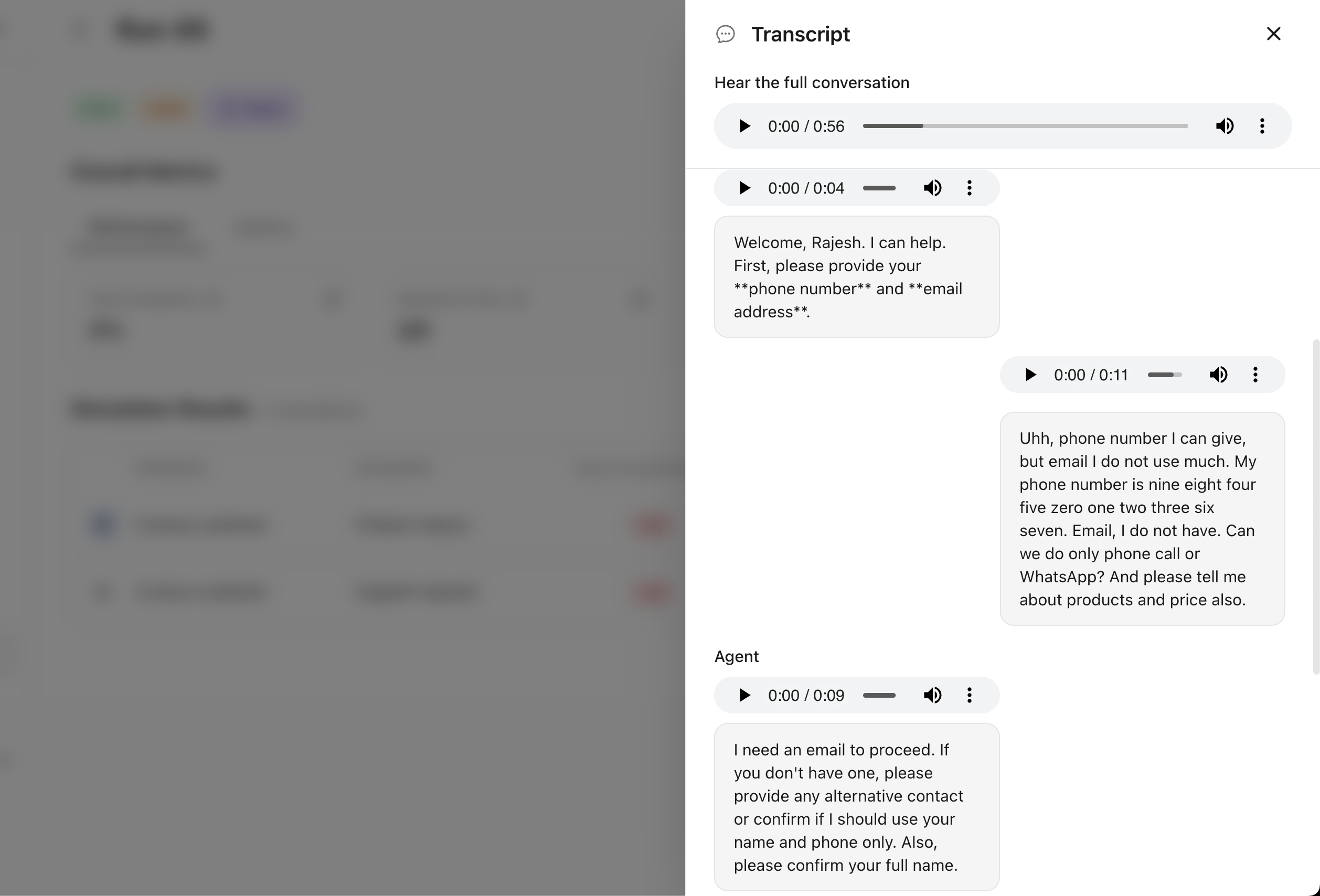
Inspect each simulation run with full transcript and generated audios for the agent and the simulated user
Simulate realistic conversations
with your agent
Catch bugs before deploying your agent to real users
Create user personas to define who your users are
Create scenarios to depict the purpose of the user's interaction with the agent
Run a simulation with personas and scenarios using custom evaluators and get performance metrics across all runs
Inspect each simulation run with full transcript and generated audios for the agent and the simulated user
Proudly open source
What we open-source is what we use ourselves. Nothing hidden behind a paywall.
Self-hosting
We can help you run Calibrate on your infrastructure to ensure sensitive data stays in environments you control
No per-seat pricing. Ever.
No per-user fees. Add staff, partners, and consultants as your team grows
Auditable, end to end
The full codebase is on GitHub for pre-deploy review and real diligence
No vendor lock-in
Fork, adapt, and make changes as you wish
Works with any AI agent stack
Supports all major models with more coming soon
Supports integrations including Deepgram, ElevenLabs, OpenAI, Google, Cartesia, Anthropic, Groq, DeepSeek, Smallest AI, Claude, Gemini, Qwen, Meta, Mistral, Cohere, Sarvam, AI21, Baidu, NVIDIA, Amazon.
Join the community
Talk to the team building Calibrate to get your questions answered and shape our roadmap
Team
Combined experience of 25+ years building AI systems


Start Calibrating today
Become a team that ships trustworthy AI agents beyond vibe checks